

Some of the problems in computer vision are motivated by their relevance to robotics and their prospective utility for systems that move and act in the physical world. However, a recent research stream in the intersection of Machine learning and robotics shows that models can be orchestrated to map raw visual input to action and this is in contrast to the belief that action is a motivation for computer vision research. If any robotic system can be trained directly for the tasks at hand with any raw image as input and no explicit vision modules, what is the utility of further perfecting models for semantic segmentation, depth estimation, optical flow, and other computer vision tasks?
This is the motivation for the research work Does computer vision matter for action? and it was authored by BRADY ZHOU, PHILIPP KRÄHENBÜHL, AND VLADLEN KOLTUN of Intel Labs, the University of Texas at Austin respectively.
EXPERIMENTS
 The researchers reported controlled experiments that accessed whether specific vision capabilities are useful in mobile sensorimotor systems that act in complex 3-dimensional simulations derived from immersive computer games used to conduct these experiments. To conduct these experiments, they used realistic three-dimensional simulations derived from immersive computer games. The game engines were instrumented to support controlled execution of specific scenarios that simulate tasks such as driving a car, traversing a trail in rough terrain, and battling opponents in a labyrinth. Then sensorimotor systems equipped with different vision modules were trained and their performance on these tasks was measured.
The researchers reported controlled experiments that accessed whether specific vision capabilities are useful in mobile sensorimotor systems that act in complex 3-dimensional simulations derived from immersive computer games used to conduct these experiments. To conduct these experiments, they used realistic three-dimensional simulations derived from immersive computer games. The game engines were instrumented to support controlled execution of specific scenarios that simulate tasks such as driving a car, traversing a trail in rough terrain, and battling opponents in a labyrinth. Then sensorimotor systems equipped with different vision modules were trained and their performance on these tasks was measured.
Two types of models were used for this experiment:
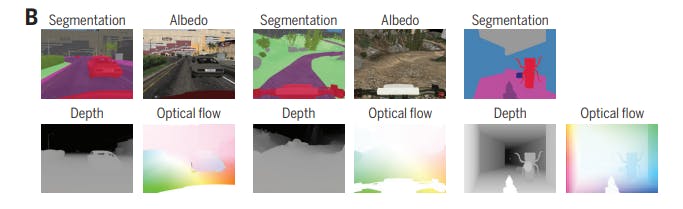
For each task, agents that either act based on the raw visual input alone or are also provided with an intermediate segmentation were trained. The intermediate representations are illustrated in the figure below.
 RESULTS AND FINDINGS
RESULTS AND FINDINGS
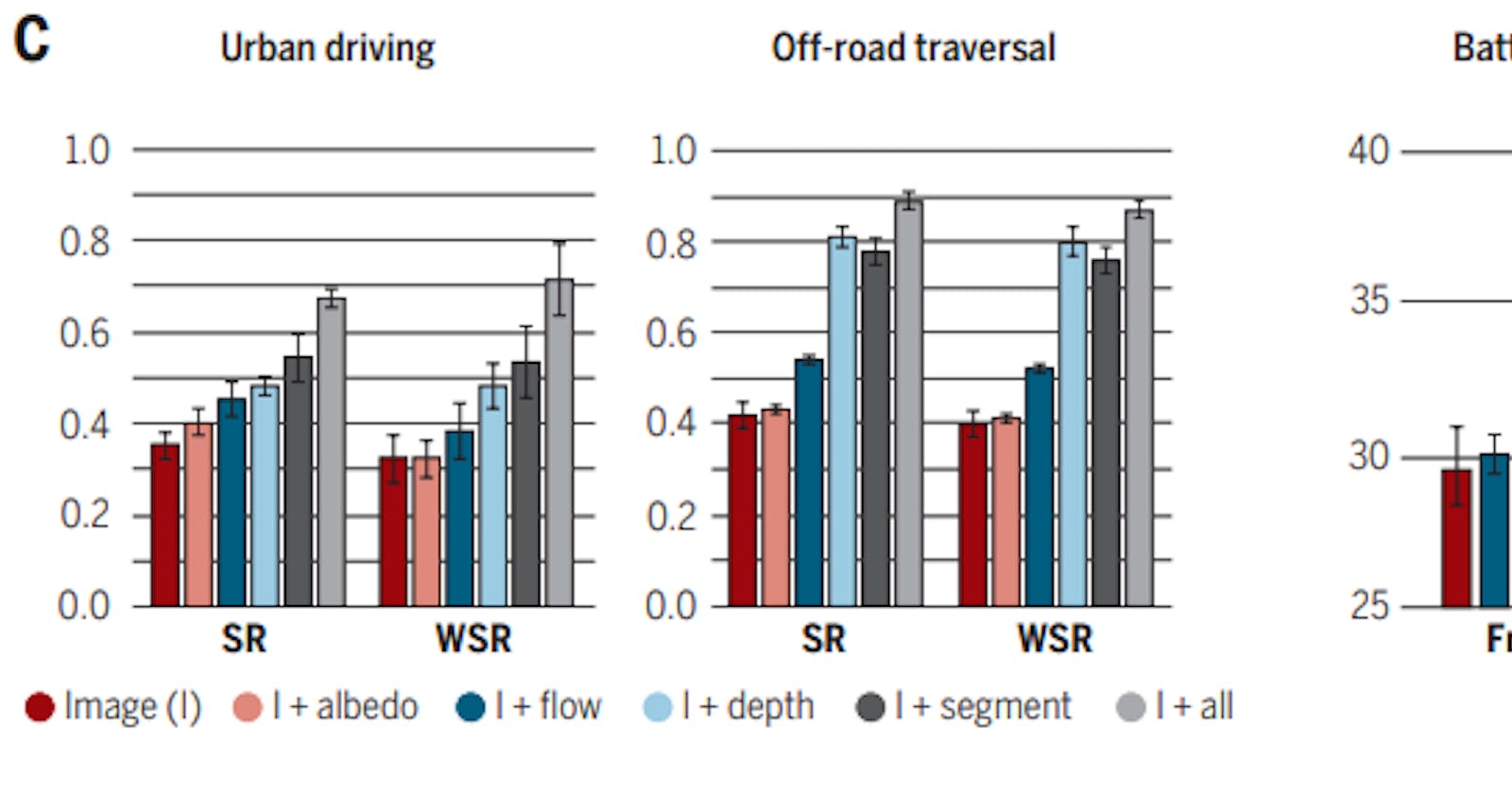
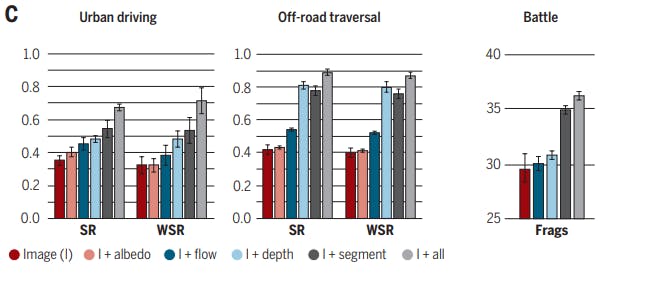 From the figure above, it is derived that:
From the figure above, it is derived that:
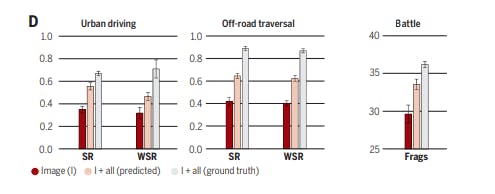
Supporting experiments. In the ‘Image + All (predicted)’ condition, the intermediate representations are predicted in the original place by a convolutional network; the agent is not given ground-truth representations at test time. The results indicate that even the predicted vision method confers a significant advantage. Explicit computer vision is particularly helpful in generalization, by providing abstractions that help the trained system sustain its performance in previously unseen environments.
CONCLUSION
In conclusion, the experiment carried out in this research work proves that computer vision does matter for action. The intermediate representations of images are indeed useful for sensorimotor tasks. Models equipped with explicit intermediate representations train faster, achieve higher task performance, and generalize better to previously unseen environments.
Original paper can be found here